Phonetic Modulation in Bilingual Speech - An Inspection of A Current Methodology
In Fricke, Kroll, and Dussias’s 2015 paper, Phonetic variation in bilingual speech: A lens for studying the production–comprehension link (Download here with UC Davis Credentials), they investigate the mechanics of codeswitching in bilingual speakers. The key findings are that the codeswitches are preceded by phonological bleed from the new target language (such as a change in voicing strategy), as well as by a net slowing of speech rate. This provides a sort of cue to prepare the listener to adjust to the speech segment’s new target language. This paper is interesting for two main reasons: the methodologies employed in their investigation, and the implications of their findings. I will let the paper serve to present its own findings (but feel free to comment the findings in the comment section below); instead, I focus here on the methodologies employed in the speech rate study of this paper. It is an excellent example of a quantitative study design leveraging existing resources in an efficient an effective manner (in practical terms I think of this as: low cost-of-execution for relatively high resolving power).
Fricke, Kroll, and Dussias are aiming specifically at speech processing with their methodology, using codeswitching as the window into the brain’s functions and as a secondary focus of investigation that is conveniently built into their structure. Their first study focuses on speech rate in codeswitching. Their methodology was highly practical in that it leveraged preexisting corpus data for a novel application. The corpus in particular was also important: while not precisely representative of the larger populace, the focus on “highly balanced” bilinguals in the Bangor Miami Corpus serves to give a more sanitary data set with fewer confounding variables. Additionally, notice how the authors sidestep other confounding variables by focusing specifically on natural codeswitching in situ, not cued language switching. This combines with an already present control population of tokens (which were selected for pairing with codeswitch sections by a reasonable set of criteria). I have an open question on whether control tokens for similar codeswitch tokens were available for re-paring to other acceptable codeswitch tokens. While I assume this is not the case, it would have been nice to see that asserted explicitly. I appreciate however that the multiple-control design allows them to test their tokens against an average rather than a random point. This is an excellent capitalization on the lopsidedness of their data (far more unilingual segments than codeswitch segments). In effect, the corpus choice simultaneously improved study controls while reducing overhead and the authors cleverly leveraged the inherently lopsided data to produce better controls.
The inclusion/exclusion criteria for codeswitch tokens garnered some raised eyebrows from me however. While they maintain a more consistent dataset by focusing purely on primary-to-secondary language switches, the justification for this selection of intentionally excluding the well documented primary language lag, I think that by introducing such lag as a problem, they then place a question on the applicability of the end findings. To state more clearly: they implicitly assert that the codeswitch language processing properties are meaningfully different from standard processing. This means, that by excluding half for known lag, they are inserting a question mark as to whether the remaining half is actually representative of normal language processing or if it is different in another, perhaps unknown, way. While this is perhaps unavoidable, it stands out as one of the axes on which their methodology leaves room for substantiation by other research.
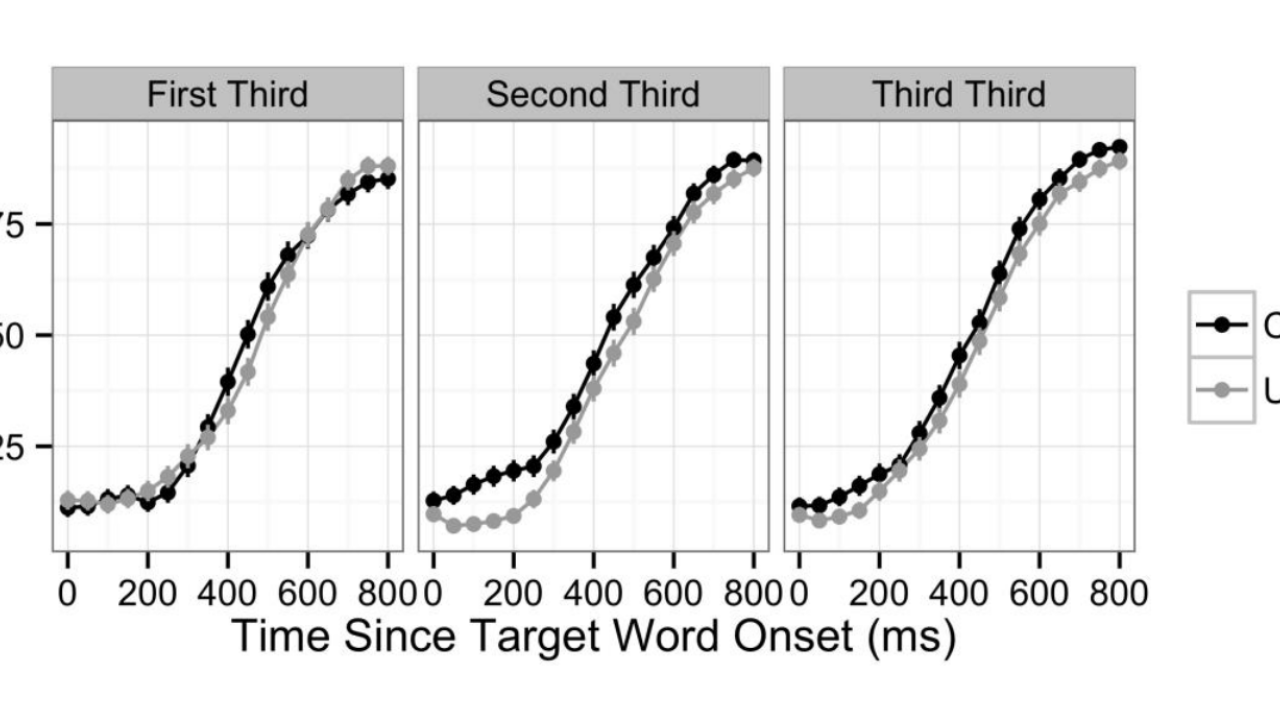
The speech rate analysis focuses on articulation rate. I think this is a good choice from the authors — again on the grounds of excluding as many potential confounding variables as possible. By excluding the inherently high-variance speech pauses, they keep to a more manageable analysis that is more likely to inform on their actual research question. The time-lapsed consistency check on the hand-marked data was unexpected, but it was good way to demonstrate the consistency of the coding employed by this study on the data set. This is a simple way to increase the rigor of the study and demonstrate that the most “discretionary” part of the process was reliably consistent. In this case, the authors found strong reliability on the onset/offset coding but a relatively high deviation on disfluency tagging. I call attention to this because it gives the ability to immediately and preemptively engage with the issues instead of discovering them post-publishing.
The purpose of the above analysis is to give a quick breakdown of how small study design decisions contributed to a rigorous and effective in vivo analysis.
Melinda Fricke, Judith F. Kroll, Paola E. Dussias, Phonetic variation in bilingual speech: A lens for studying the production–comprehension link, Journal of Memory and Language, Volume 89, August 2016, Pages 110-137, ISSN 0749-596X, http://dx.doi.org/10.1016/j.jml.2015.10.001. (http://www.sciencedirect.com/science/article/pii/S0749596X15001187)
About the Author:
Ben Gomes is PhD student in the UC Davis Linguistics Department with research focused on language change and typology.